E-commerce, driven by multiple new channels, is a booming business. “The NRF expects that online retail will grow 8-12%, up to three times higher than the growth rate of the wider industry, racking up nearly $445 billion in sales.” But today’s consumers no longer purchase in a silo; they read customer reviews on social media, attempt to price match on Amazon before ever heading in-store, and visit brand websites to understand product details. Buyers visit a site an average of 9.5 times before making a purchase. More than ever, the consumer purchase journey is evolving into an ever-expanding range of online and offline channels and interactions. As these hyper-connected consumers increasingly rely on a variety of digital and physical resources when making purchase decisions, how then do ecommerce marketers effectively engage them AND get more get ROI from their media spending?
Ecommerce marketers are adapting their strategies to deliver the right ads with the right offers at the right time and through the right channels & devices
Marketers know that the shopping landscape is changing drastically with the rise of new channels, content, and connected devices. As reported in Ad Age:
- Shoppers will use smartphones in over one-third of total U.S. retail sales in 2018 for researching, comparing prices and purchasing.
- 88% of consumers research their purchases online before buying, whether it’s online or in-store.
- 65% compare the in-store price with the online price while in the store. Shoppers who use multiple channels to conduct product research spend 14% more than single-channel shoppers.
Hyper-connected consumers expect a highly personalized experience from all their interactions including organic search, retargeting ads, paid search, remarketing email and/or direct mail offers. They expect you to know them, show them you know them, and help them at every touchpoint. Poor performing campaigns will flop with shoppers, wasting dollars and costing you lost sales. As a result, marketers are rapidly converging channels, content / offers, and devices along the consumers’ purchase journey, where having the ability to track, measure, and optimize each touchpoint has become the secret weapon. Yet many marketers continue to use antiquated attribution models, like last touch, to determine how they optimize their touchpoints to maximize sales and ROI.
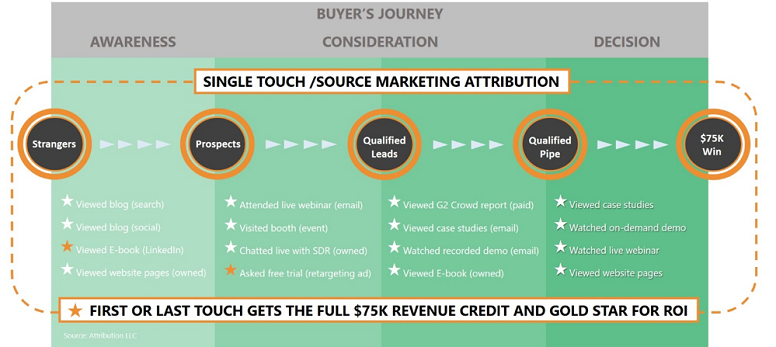
But last or single-touch attribution is ineffective for an omni-channel / content / device world
Single-touch attribution consists of first touch and last touch models, giving the full credit of the sale to the touchpoint a consumer interacted with first or last such as a promotional email or a display ad. Any interactions before or after that, clicking a Facebook or paid search ad, for example, are not credited with the sale. According to retail marketing strategist Mike Farrell, attributing a sale wholly to the last (or first) interaction before the purchase is outdated and inefficient. The customer journey has grown increasingly complex, so optimizing for a single action or channel ignores a much bigger picture of how consumers engage with your touchpoints on their way to purchase. A customer, for example, may discover a new product on Pinterest, rediscover that product through display ad retargeting, research the product via Amazon, and finally make the purchase after receiving a promotional email and/or direct mail. This journey can occur across desktop and mobile devices.
Valuing only the last touch ignores the very important role each marketing activity had in driving the sale and limits marketers’ ability to develop greater cross-channel cohesion. That’s because you can overly emphasize top or bottom-funnel activities, neglecting touches across the full purchase journey. Ecommerce marketers need to know the effectiveness of each marketing touchpoint in every consumer journey regardless of where those touchpoints occur. Without the ability to track this and tie interactions across channels, content, and devices to one user, it’s virtually impossible to know which marketing initiatives are working and which ones aren’t.
Last-touch attribution is inadequate for tracking today’s real-world touchpoints and hyper-connected journey, resulting in missed revenue and misspent dollars.
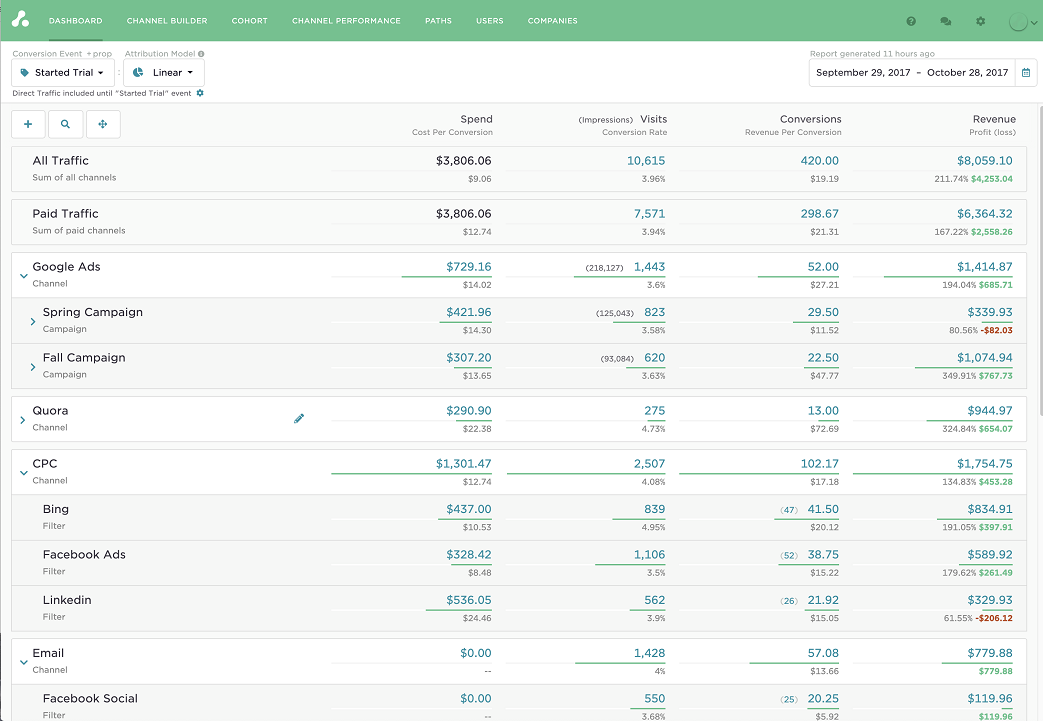
Multi-touch attribution connects real-world touchpoints and devices to consumer journeys and provides a single version of return on spend
By reconciling all available touchpoints to a unique consumer identity, multi-touch attribution helps marketers see precisely how each consumer moves through the purchasing funnel and reach them on their preferred channels. The granular detail allows them to better understand how customers interact with their media, more accurately attribute credit to each interaction, and more effectively optimize their media buying. Since this insight is produced in near real-time, marketers can quickly capitalize on opportunities to improve engagement and influence purchase decisions at each stage in the consumer journey.
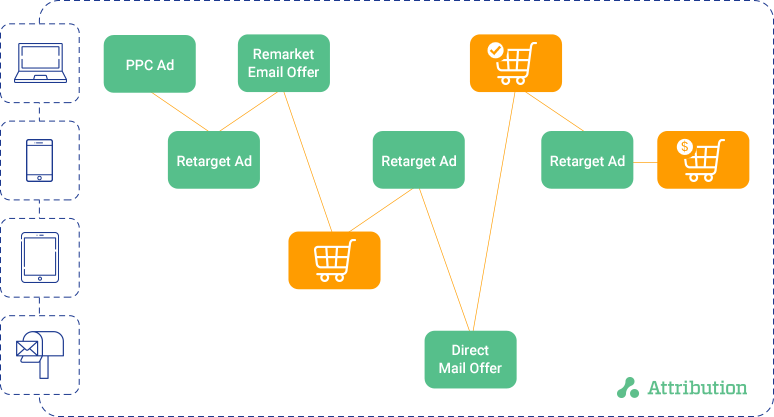
Once linked, identities previously attached to multiple devices are collapsed into a single identity. This cross-device attribution gives marketers a view of the end-to-end consumer journey. By linking touchpoints and devices to a single person and journey, marketers can clearly see when they are serving too many ads to the same person or when two or more display vendors are overlapping each other serving ads across the same domain. Multi-touch attribution can help marketers understand exactly which factors are driving shoppers to convert and fine-tune their tactics to influence their decision to buy and deliver a successful experience that wins over new customers, and keeps existing ones coming back for more.
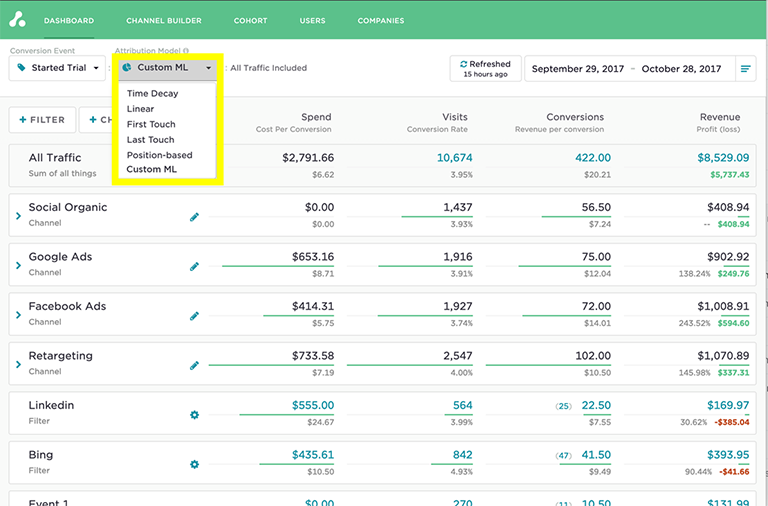
Multi-touch attribution uses different models to meet your needs
While single-touch attribution only gives credit to one touchpoint, multi-touch attribution models assume all touchpoints play some role in influencing a sale. Some popular models are:
Linear multi-touch attribution model is the baseline for multi-touch attribution models. It assigns an equal percentage of revenue credit to each touch regardless of its recency in the buying journey.
Time-decay multi-touch attribution model assigns revenue credit to each touch based in accordance to its recency in the buying journey. The closer the touch was to the sale or conversion event, the more influential it was.
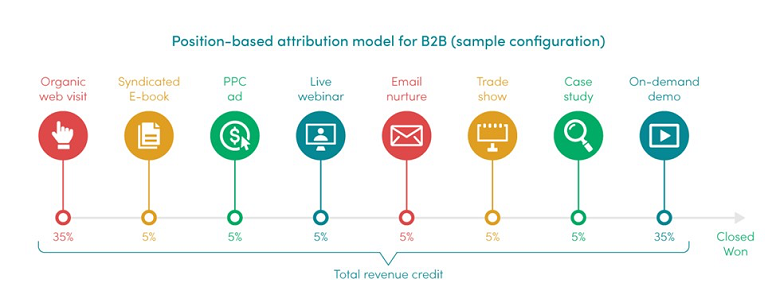
Position-based (or U or W-shaped) multi-touch attribution model gives 40% revenue credit to the first and last touch, with the remaining 20% applied equally among the rest of the touches. A modern multi-touch attribution platform allows you to configure these percentages.
Data-driven machine learning multi-touch attribution model uses historical touch and conversion data with machine learning to derive a custom algorithm to assign revenue credits to touches.
There’s no perfect science for choosing the right multi-touch attribution model. As the use of multi-touch attribution technology evolves, marketers will run several models concurrently to see which one is right for their business. The good news is modern multi-touch attribution tools allow you to see and compare the results from each model.
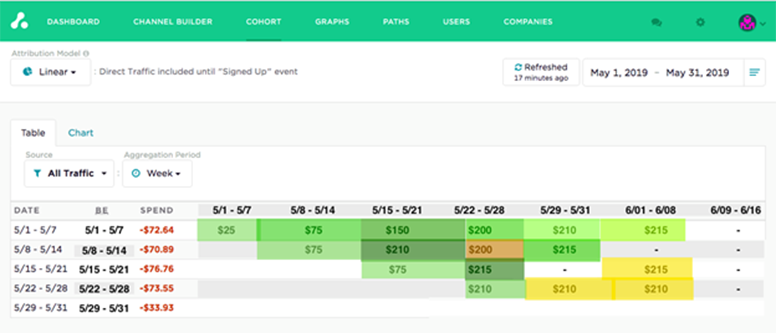
Multi-touch attribution uses cohort analytics to give you deep insight to optimize acquisition channels and campaigns.
Cohort analysis the most effective ways to gather information about your channels and campaigns. A cohort method quantifies the ROAS of your channels and campaigns based on a cohort (date or date range) and captures the spend and stream of conversions to report profit, break-even and even lifetime value. In multi-touch attribution, your cohorts may look something like this:
How much revenue did we generate today? this week or month?
How long does it take for my ad spend to break-even?
How are we trending by channel? which ones are consistently delivering top ROAS?
Modern cohort analytics allow you adjust cohorts (without spreadsheets) to any date or date range and easily visualize ad performance, discover patterns, and optimize channels and campaigns in real-time to quickly optimize your channels and campaigns.
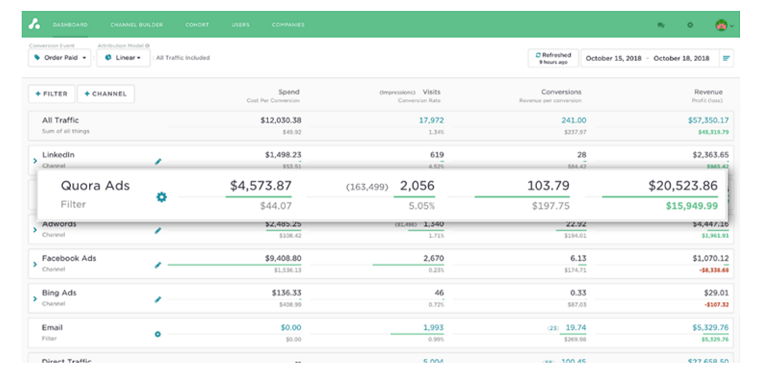
Multi-touch attribution keeps your advertising channels honest about their ROAS
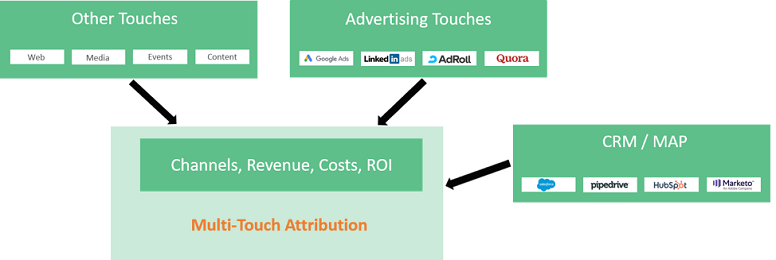
Because advertising platforms each use their own pixel to track ad performance, your conversion counts can easily become overstated. For example, let’s say Molly is shopping for a laptop and clicks on your Google search ad on Sunday; clicks on your AdRoll retargeting ad on Tuesday; and on Friday she clicks on your Outbrain native ad which takes her to your site where she purchases a laptop for $600. In this purchase scenario, Google, AdRoll and Outbrain reports show 3 unique conversions totaling $1,800, but your ecommerce system only shows 1 conversion to 1 buyer at $600.
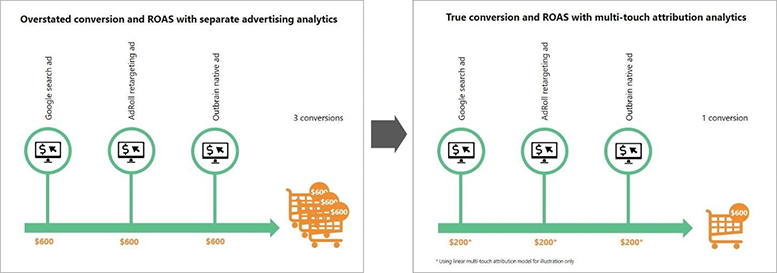
Multi-touch attribution automatically connects campaign details from Google Ads, AdRoll, Outbrain, and other advertising platforms to the consumer purchase journey and allocates a portion of the revenue credit (total not to exceed 100%) to each touch in accordance to their role in influencing the purchase. This built-in reconciliation eliminates the over-counting problem associated with using conversion data from each platform to guide your ad spending. Having this true ROAS insight (along with cohort analytics) also allows you accurately compare the performance of each advertising platform to what’s really converting (or not) and confidently rebalance your total spend to maximize revenue and return.
Multi-touch attribution works hand in hand with your ecommerce platform
Multi-touch attribution doesn’t replace your ecommerce platform – it complements and enhances it. It enables ecommerce platforms such as Shopify and WooCommerce to do what they do best: automate and scale back-end functions and consumer-facing activities and transactions for your storefront. Concurrently, multi-touch attribution focuses solely on quantifying which marketing touches, campaigns, and channels are working (or not) to help ecommerce marketers make better decisions across the entire purchase journey.
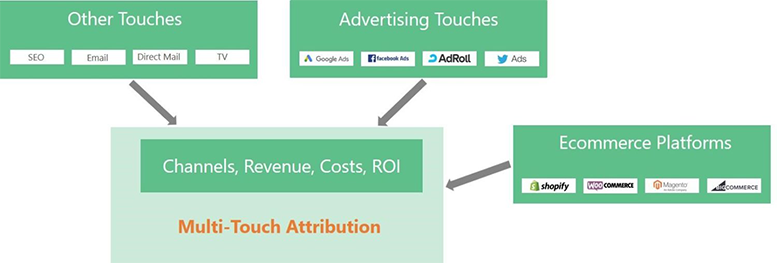
Multi-touch attribution also complements your ecommerce platform by integrating synergistically and standardizing the attribution method to see an unbiased impact of every customer interaction from search keywords to retargeting ads to direct mail offers. It enhances workflow with existing tools and channels and eliminates the chaos and inefficiency of extracting and normalizing channel-specific analytics. It also provides the data that fuels effective budgeting and optimization by helping marketers to know where to place their best bets to drive efficient revenue growth.
Ecommerce marketers should plan for multi-touch attribution.
Consumer expectations for relevant and personalized experiences have soared. Winning their business means understanding their unique preferences and behaviors, as well as the marketing messages and offers that influence their decision to buy. With a true understanding of their customers and the tactics that influence their decision to buy, marketers can deliver a successful omnichannel / device experience that wins over new customers and keeps existing ones coming back for more.
While it may seem daunting, moving away from last touch or first touch attribution models will quickly become an imperative for retailers. As consumer journeys have grown in complexity, marketers need to ensure their attribution models keep up. With multi-touch attribution, ecommerce marketers can understand consumer interactions across different channels and devices, spend smarter than their competitors, and improve consumers’ overall shopping experience to encourage conversions.